프로그래밍을 하다 보면 '추상화'라는 단어는 늘 주위에 존재한다. 너무 흔하게 사용될 수 있는 용어라 가끔은 의미에 어긋남에도 혼용될 때도 있다. 대충 코드 내에서 중복되는 부분을 발견한 다음 따로 추출하여 공통화하면, 그걸 추상화라고 말하는 경우도 있으니까.
사전적 의미
추상화라는 단어를 설명하기 위해 가장 적절한 문장을 고르라고 한다면, 아마 다음과 같을 것이다.
복잡한 내부 구현은 감추고 필수적인 기능만을 외부에 노출하여 단순화하는 과정
추상화는 OOP의 대표적인 특징 중 하나로 꼽히는 개념이다. 그렇지만 꼭 프로그래밍 측면이 아니더라도 이 의미는 어디에서든 통용될 수 있다. 가령 어떠한 분야를 공부하면서 전문성을 쌓을 수 있는 까닭은, 밑바닥의 세부 요소를 하나씩 이해해 가면서 그것을 일반화(추상화)한 뒤 그것을 토대로 더 고차원적인 깊은 학습, 사고를 할 수 있기 때문이다.
프로그래밍도 마찬가지다. 어떠한 계층에서 세부 구현은 감춘 뒤 상위 계층에 인터페이스를 제공하겠지만, 전달받은 상위 계층 내의 로직이 쌓이다 보면 어느 순간 그 계층에서도 추상화가 가능한 영역들이 생기게 되고 그렇게 되면 더 고차원적인 맥락을 다루는 계층이 생기게 된다.
추상화의 예시
대개 추상화를 설명하기 위해 자주 드는 예시는 '자동차'인 것 같다. 'Absctraction in programming example'이라는 키워드로 검색해 보면 객체 지향 프로그래밍을 다루는 아티클과 함께 아래와 같은 이미지를 쉽게 발견할 수 있다.
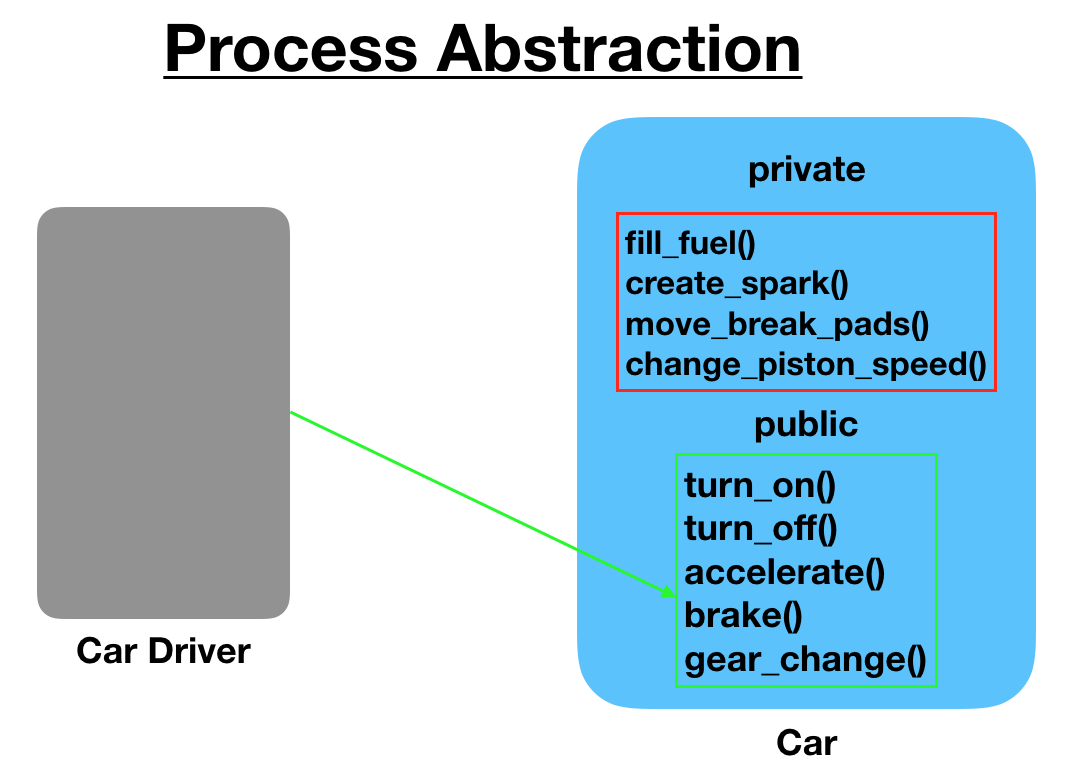
(아티클을 자세히 읽진 않았지만) 이미지만 보면 대강 접근 제한자(private, public)로 구분하여 사용자가 알아야될 부분과 내부의 세부사항을 구분해 둔 느낌이다. 사용자는 시동, 액셀, 브레이크, 기어만 알면 운전을 하는데 전혀 무리가 없다. 그리고 이 예시만 보았을 때 우리가 프로그래밍 내에서 추상화라는 대강의 느낌을 이해하는 데도 무리가 없다.
근데 막상 이걸 프론트엔드 개발로 끌고 오면, 추상화를 제대로 이해하고 적용하기가 여간 쉽지 않다. React로 작성하는 코드는 OOP와는 거리가 먼데? 백엔드에서 받아오는 데이터를 컴포넌트에서 보여주기만 하면 되지, 추상화가 어디에 필요한데? 문제는 여기서부터 발생한다.
잘못된 추상화로 인한 문제

프론트엔드 내에서 백엔드의 데이터를 받아와 화면에 보여주고 화면에서 사용자의 이벤트(입력, 클릭 등)를 받아 다시 백엔드로 보내는 과정을 최대한 단순화하면 위 그림과 같을 것이다. '이 정도면 잘 분리되었군' 하겠지만, 프론트엔드 개발자로서 다음과 같은 경험을 마주한 적이 있다면 한 번쯤은 뭐가 문제인지 고민해 볼 필요가 있지 않나 싶다.
- 백엔드에서 api 응답 구조가 수정되면, 중간 계층을 넘어 view까지의 수정이 불가피함
- 기획과 연관된 비즈니스 로직이 여러 계층에 산재되어있음
- 컴포넌트에서 직접 판단하고 view를 (때로는 아주 복잡하게) 분기 처리하여 그리는 로직이 있음
- (새로운 작업자 입장에서) 어떠한 동작 과정을 유추하기 위해 여러 계층을 유랑해야 함
추상화라는 건 두 계층을 연결하는 다리이며 동시에 복잡성을 감추는 필터와 같다. 그리고 계층 간 관계는 '상위 - 하위' 혹은 '사용자 - 제공자'로 나눠질 수 있다고 생각한다. 강아지, 고양이, 새 등을 '동물'이라는 개념으로 추상화하는 것은 '상위 - 하위'의 개념으로 볼 수 있다. 이러한 관점으로 OOP에서 추상화를 활용하여 상속, 인터페이스, 다형성을 활용하여 유연한 설계를 할 수 있다. 하지만 사람과 차의 관계는 '상위 - 하위'보다는 '사용자 - 제공자'에 가깝다. 차는 사람에게 액셀, 브레이크라는 인터페이스를 제공하면, 사람은 그 인터페이스로 차를 활용하여 '운전'이라는 행위를 할 수 있다.
문제 제기에 앞서 사전 설명을 이토록 길게 한 이유는, 위에 그려둔 레이어들을 각각의 상대적인 '사용자 - 제공자'로 바라보게끔 하기 위해서다. 양쪽 끝 단만 보자면, View는 사용자이고 Server는 제공자이다. View는 제공자인 Server로부터 데이터를 받고 Server에서 제공하는 API를 호출하여 새로운 응답을 받거나 화면에 존재하지 않지만 실제 앱을 이용하는 유저의 실생활에 영향을 미치는 동작을 수행한다. (e.g. 배달, 장보기, 스트리밍 등) 이제 좀 더 나아가 이것을 보다 세분화한 단계로 나누어 각 계층을 서로의 사용자와 제공자로 바라보도록 하자.
- 사람은 앱(View)을 사용한다. (User Interface)
- View는 자신을 새로 그리고 조작하기 위해 State를 사용한다.
- State는 서버의 데이터를 가져와 자신을 만들기 위해 API를 사용한다. (Application Programming Interface)
제공자는 사용자에게 사용법을 제공하기 위해 인터페이스를 제공한다. 사용자는 제공자가 제공하는 인터페이스 외에 세부적인 구현사항은 몰라도 된다. (오히려 몰라야 한다에 가깝다)
자, 이러한 연결 고리 속에서 추상화를 고려하지 않고 코드를 작성했다면 어떻게 될까? 이제 각 계층의 상대적인 사용자는 제공자 측에 숨겨져 있던 세부 구현의 확인과 조작이 가능하다. 아마 다음과 같은 일들이 자연스레 따라올 것이다.
- 사용자는 어떠한 동작을 수행하기 위해 필요 이상의 지식을 알아야 한다.
- 제공자 측의 세부 구현 사항이 바뀌게 된다면, 동일한 동작을 위해 사용자도 그에 맞게 대응을 해야 한다.
- 사용자의 부주의로, 혹은 악의로(사용자가 사람이라는 전제 하에) 제공자를 망가뜨릴 수도 있다.
이 상황을 앞서 설명한 사람과 차의 예시로 돌아가 설명해 보자면, 영화 속 클리셰 중 하나인 '시동을 거는 장치가 고장 나 내부 전선을 마찰시켜 시동을 거는 장면'을 연상해 볼 수 있을 듯하다. 운이 좋아 원하는 동작을 수행하는 데 성공했다지만, 사실은 정상적인 상황이 아니다.

이것은 전체의 흐름 중 특정 계층 사이만 잘 막아둔다고 해결되는 문제가 아니다. 모든 계층은 연결되어 있기 때문에 추상화가 잘 되어 있지 않은 부분을 기준으로 최종 사용자 측면으로 넘어갈수록 문제는 계속 존재하게 된다.
프론트엔드에서의 추상화
IT 회사에서 풀스택 개발자로만 이루어져 있어 각 기능에 대한 프론트엔드, 백엔드 영역을 한사람이 일당백으로 처리하는 환경은 거의 없다. 즉 프론트엔드 팀, 백엔드 팀이 이격 된 채 각자 맡은 바의 일을 하게 될 가능성이 크다. 운이 좋아 의사소통이 원활하고 팀워크를 중시하는 백엔드 개발자를 만나 프론트엔드의 변경 범위를 잘 고려한 요청, 응답 구조를 내려준다고 한들, 제공자인 백엔드의 세부 구현 변경으로부터 프론트엔드의 코드 변경은 자유로울 수 없다는 얘기다.
그렇기에 백엔드의 사용자인 프론트엔드는 백엔드 코드 변경으로 인한, 또한 어쩌면 프론트엔드 코드베이스의 코어 모듈 수정으로 인한 무자비한 코드 수정을 최소화하기 위해 계층 간의 적절한 추상화를 도모함으로써 독립성을 보장할 필요가 있다. 비단 수정 범위뿐만 아니라 독립성을 유지함으로써 계층 간 관심사를 통합하면, 비즈니스 로직을 한 데 응집시킬 수 있어 기획에 대한 이해 속도가 빨라지고 최종 사용자인 View는 이미 계산이 끝난 상태만을 받아와 이것을 어떻게 보여줄지에 대해서만 관심을 갖게 하기에 코드가 훨씬 단순해진다.
위 목적을 충족하기 위해 시도해 볼 만한 사항은 아래 두 가지로 간추려볼 수 있다.
1. 백엔드 응답을 인자로 받아 프론트엔드에서 관리할 Model을 반환하는 계층을 만들어 '백엔드 응답'이라는 세부 구현을 감추기
2. Model을 인자로 받아 View가 사용할 상태를 반환하는 계층을 만들어 '비즈니스 로직'이라는 세부 구현을 감추기
추가된 계층을 기존 다이어그램에 녹여보면 아래와 같은 형태로 확인할 수 있다.

이제 백엔드의 요청, 응답 구조가 변경됨에 따라 대응해야 할 부분은 Data <-> Model을 서로 변환시켜주는 계층뿐이다. 그리고 프론트엔드 내에서 다룰 모델 구조가 변경되어야 한다면, 마찬가지로 Model 자체와 Model -> State로 변환하는 계층만 수정해 주면 된다. 결론적으로 말하고자 하는 추상화의 이점 중 하나는, 제공자 계층의 변경으로 인해 밀물처럼 밀려드는 코드 수정을 인접 계층 내에서 일차적으로 마무리할 수 있도록 일종의 '방벽' 역할을 해준다는 점이다. 이는 새로운 기능 추가나 외부의 변경 사항 대응을 위해 기존 구조를 더 확장성 있게 바꾸려고 할 때 그 효과를 여실히 체감하게 된다.
개발자는 늘 확장성 있는 구조를 염두에 두고 코드를 작성하고 싶지만, 비즈니스 요구사항은 어느 방향으로 어떻게 도출될지 아무도 모른다. 그렇기에 처음부터 확장성 있는 구조가 아닌, '확장에 용이한 구조'를 만드는 것을 목표로 삼는 것이 좋다고 생각한다. 확장에 용이하다는 것은 무언가의 수정으로 인한 추가 수정과 추가 수정으로 발생하는 사이드 이펙트를 최소화할 수 있는 구조다. 추상화는 이러한 맥락에서 적절한 대안을 제시할 수 있는 패러다임이라고 본다.
추상화의 단점
추상화가 무조건적으로 코드 작성량을 줄여주는 건 아니다. 오히려 계층이 추가될수록 복잡성과 코드 작성 수준은 어느정도 비례해서 올라간다. 이는 계층이 생기면서 확장성과 유지보수성은 증가하지만, 그에 따라 각 계층 별 명확한 책임과 추상화로 인한 제약 사항을 지키기 위해 발생하는 일종의 트레이드 오프다. 리팩터링 작업을 하면서 특히나 크게 느끼는 지점은 이렇다.
- 데이터 접근자(obj.key), 비교 로직(obj.a === obj.b)과 같은 아주 간단한 코드도 View가 Model에 바로 접근하지 않고 State로 사용할 수 있도록 변환 계층으로 한번 감싸줘야 할 때
model.data // X
Model.method.getData(model) // O
model.data === model2.data // X
Model.method.compareData(model, model2) // O
- 여러 계층으로 이루어진 Model에서 저수준 Model의 필드 추가, 수정 시 저수준 Model에서 관련 비즈니스 로직 메서드를 추가 후 View와 맞닿아 있는 고수준 Model까지 연결시켜줘야 할 때
// low level model
function getData(model) {
return model.data
}
// middle level model
function getLowModelData (model) {
return LowModel.method.getData(model.lowModel)
}
// high level model
function getLowModelDataInMiddleModel (model) {
return MiddleModel.method.getLowModelData(model.middleModel)
}
function View () {
const model = getHighModel()
const lowLevelData = HighModel.method.getLowModelDataInMiddleModel(model)
...
}
가끔은 귀찮기도 하지만, 이건 어쩔 수 없이 감내해야 하는 부분으로 봐야할 듯 싶다.
'Development' 카테고리의 다른 글
| [리팩터링 후기] Model은 View를 아예 몰라야 할까? (feat. View Model) (0) | 2025.02.01 |
|---|---|
| [23.09.26] 프로젝트의 초기 렌더링 성능 향상시키기 (2) | 2024.01.09 |
| [23.07.29] 프론트엔드에서 Route를 확장성있게 관리하기 (0) | 2024.01.09 |
| [22.09.03] 실무 프로젝트에서 Virtual Scroll 활용하기 (1) | 2024.01.09 |
| [22.04.21] Data Fetching in Next.js (1) | 2024.01.09 |


